Modify the Reward Function with the OpenAI Integration Tool
by Mathieu Poliquin
Reward Farming in Super Mario Bros 3

The problem
This blog post is about how to modify the reward function using the OpenAI Integration Tool. If you are familiar with RL then you know that the how it is caculate and scale the reward will have a huge impact on performance.
As you can see from the GIF above PPO2 algo learned to to jump on the shell to gain points and come back to make it respawn and re-jump on it and so on. This is because the reward function is only taking into account the total score.
The Solution
In order to make Mario go through the level we need to define a different one, based on his position in the level to give him points everytime he moves forward.
Step 1 - Load the SuperMarioBros3-Nes rom
If you haven’t compiled the gym_integration_tool, you can find instructions in previous post here
Step 2 - Add a new variable
At first you can see there is three variables exposed from the rom:
- lives
- score
- time
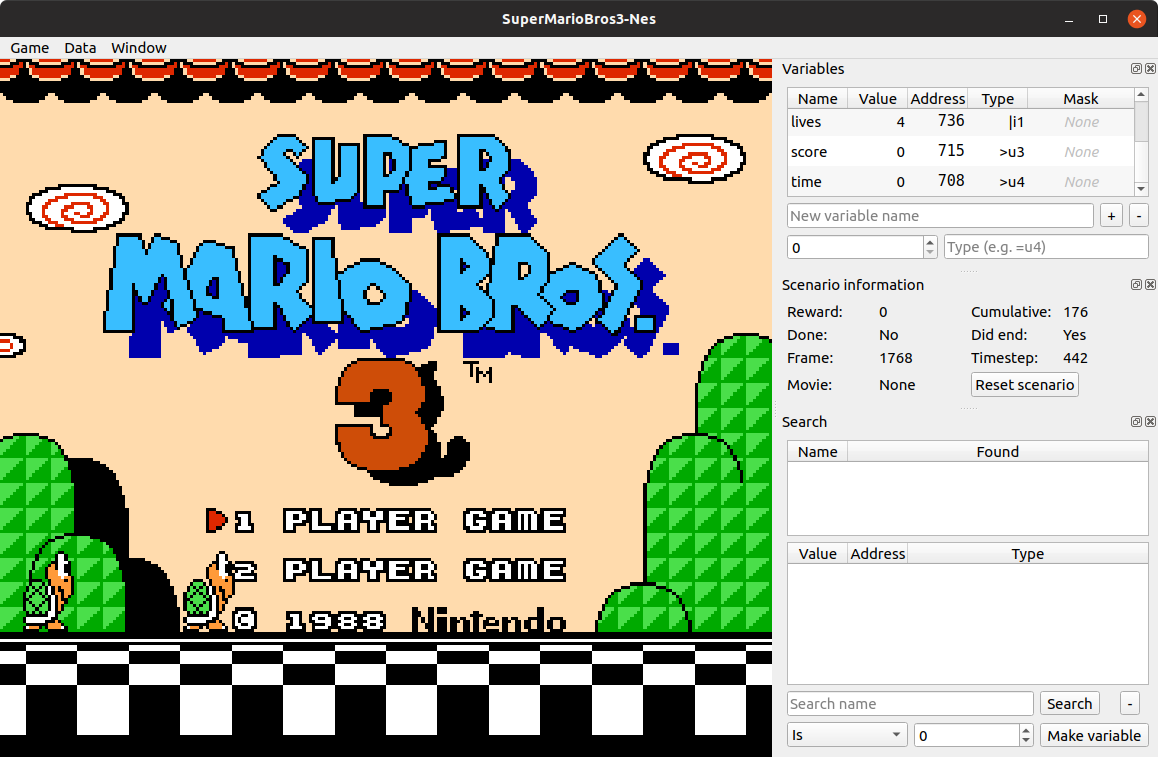
We are going to expose another variable based on horizontal position. You can named it hpos with the |u1 type.
After you filled it in (similar way to the screenshot bellow) you can click the + button
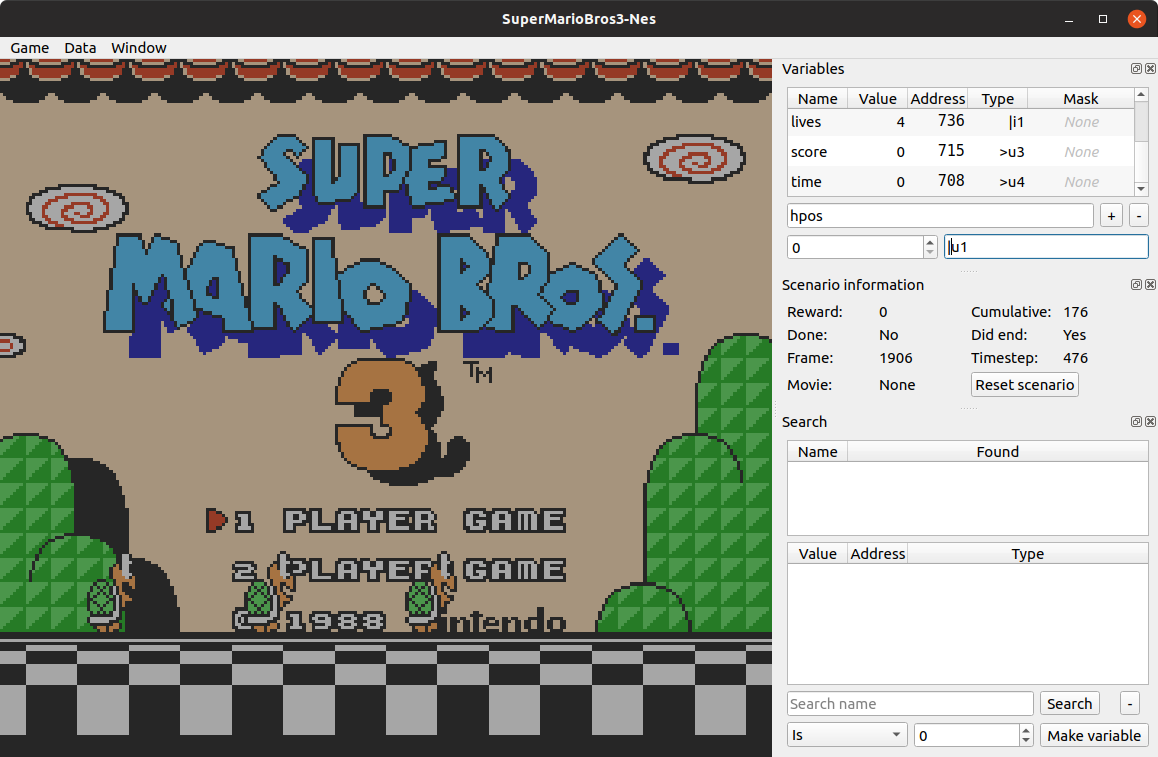
Next it to specify at which address in RAM this information can be found.
In our case it’s 090
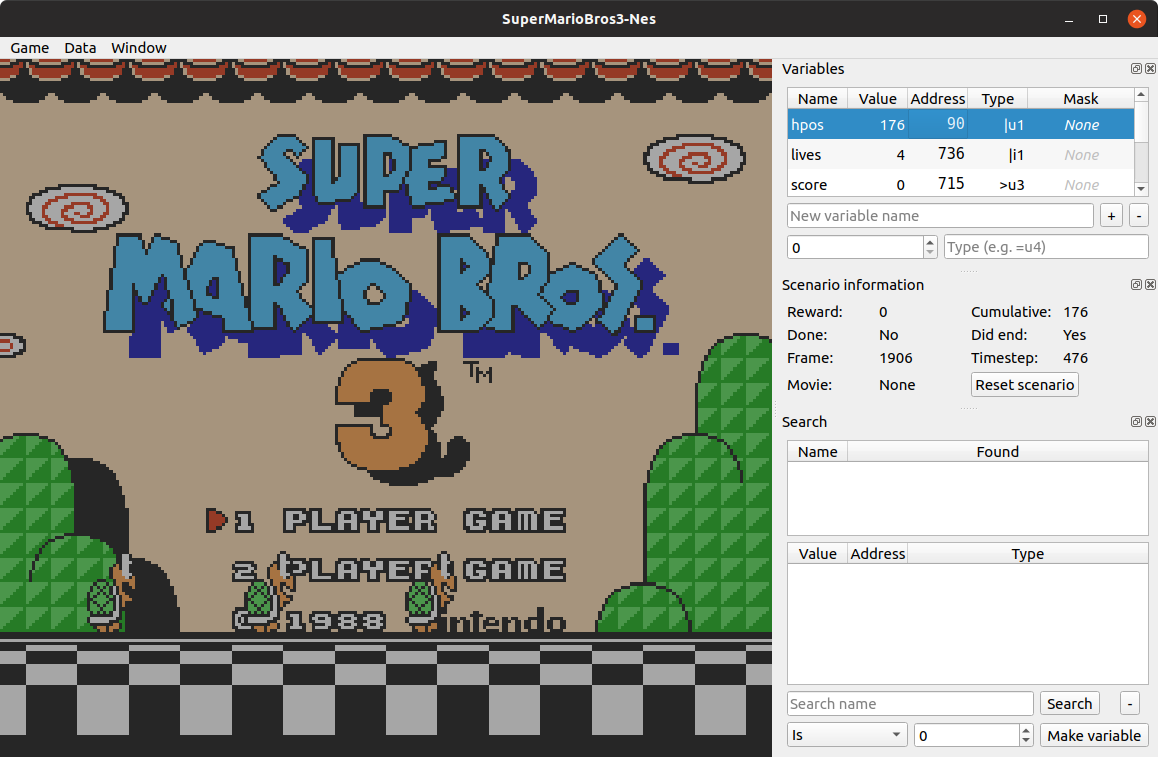
Tip: How to know where is a given variable in RAM? Lots of popular games already have people who reverse engineered them and map out most of the interesting information. For example the RAM map of Super Mario Bros 3: romhacking.net
Otherwise you can use the integration tool to help you. An example of how to find the RAM position of lives in a rom is given the OpenAI’s original blog post here
So the result is that your data.json file should look like this:
{
"info": {
"hpos": {
"address": 144,
"type": "|u1"
},
"lives": {
"address": 1846,
"type": "|i1"
},
"score": {
"address": 1813,
"type": ">u3"
},
"time": {
"address": 1800,
"type": ">u4"
}
}
}
Step 3 - Edit Reward Function
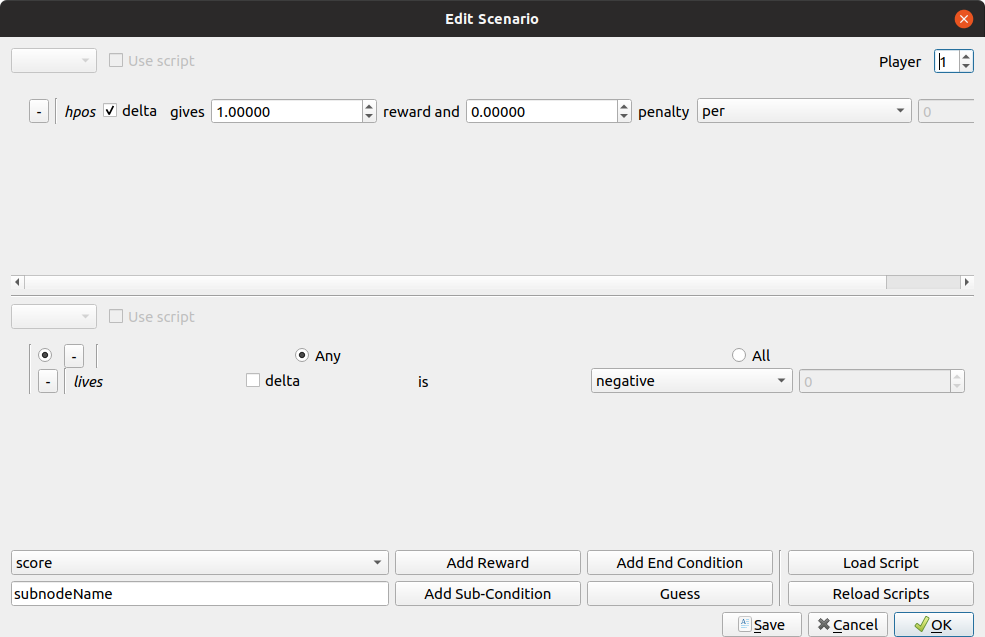
The resulting scenario.json file should look like this:
{
"done": {
"variables": {
"lives": {
"op": "negative"
}
}
},
"reward": {
"variables": {
"hpos": {
"reward": 1
}
}
}
}
Step 4 - Test it
I trained it for 120M frames
python3 -m baselines.run --alg=ppo2 --env=SuperMarioBros3-Nes --num_timesteps=12e7 --save_path=~/SMB3_120M_hpos_reward
Now Mario should play like this:

already modified reward function
EDIT 2021: I have a made a video where I go over the setup process and talk about Reinforcement Learning concepts
tags: machine learning - openai - rl - reward - integration tool - farming