Using AMD and Intel GPUs on Windows with Tensorflow DirectML
by Mathieu Poliquin
Recently Microsoft released a preview of their DirectML backend for tensorflow.
This backend enables support for most DirectX 12 devices on Windows including AMD and Intel integrated GPUs.
This is very good news because the default CUDA based backend that is locked to NVIDIA cards and ROCm (for AMD cards) only works on Linux and doesn’t support all AMD cards. So up until now lots of users could not leverage their GPUs with tensorflow
links:
As Microsoft mentionned this is a preview and not all ops are supported which means low performance on certain benchmarks and use case
Hardware setup
Hardware specs:
- ======== desktop ===========
- RX 580
- Dual Intel Xeon 2680v2
- 64GB DDR3
- ======== laptop ===========
- Intel i7-8550U
- 16GB DDR4
- Intel UHD Graphics 620
- nvidia mx150 2GB
Software:
- Windows 10 2004 - OSbuild 19041.329
- Tensorflow 1.15.3 (Vanilla and DirectML versions)
- python 3.7
- Compared with Ubuntu 19.10
installation
First Install python 3.7: download here
Next install tensorflow directML:
pip install tensorflow-directml
If you are using Windows Subsytem for Linux you need to install the AMD preview drivers first: download here
Benchmarks
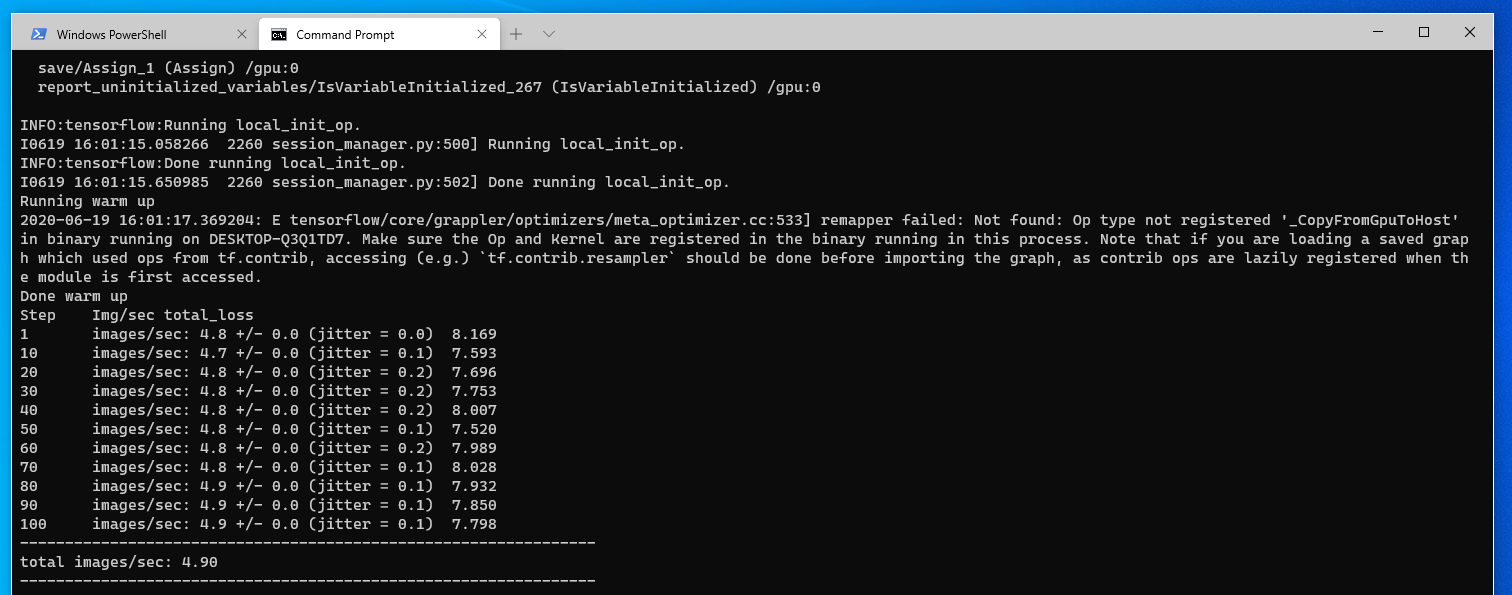
RX 580 tests
At a Windows shell (or you can use GitHub desktop app to sync the repo)
git clone git@github.com:tensorflow/benchmarks.git
cd benchmarks/scripts/tf_cnn_benchmarks
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=32 --model=resnet50 --variable_update=parameter_server
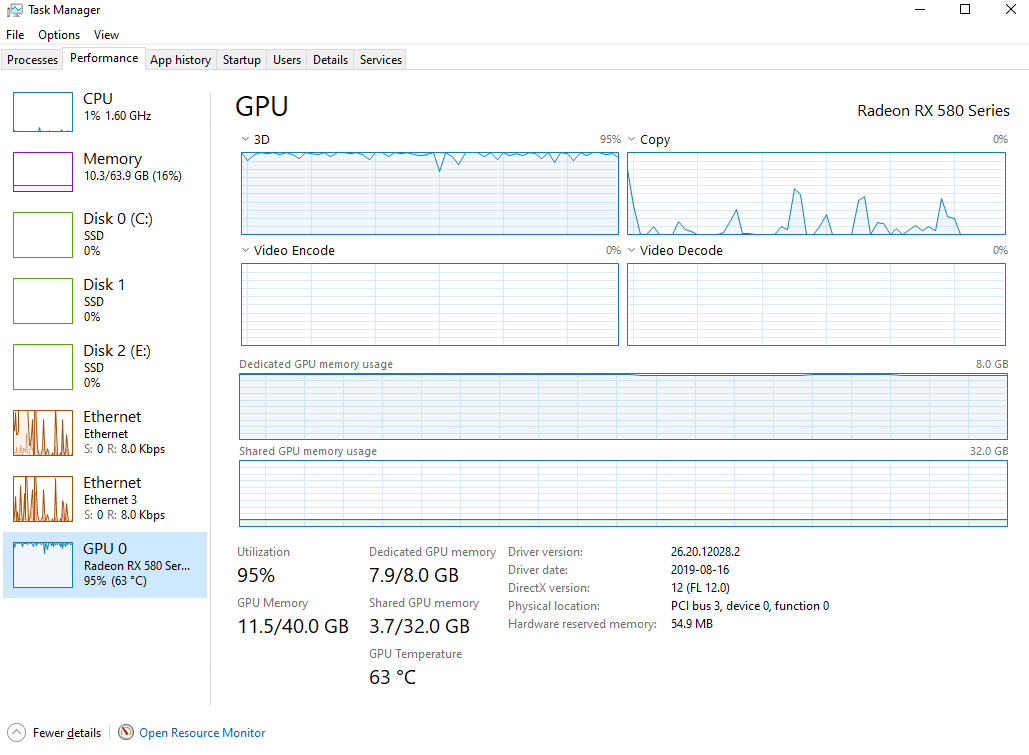
As you can see the screenshots bellow the performance is quite low compared to ROCm 3.3 where you get around 88 frames/s. One of the reasons for this is lack of support for some ops.
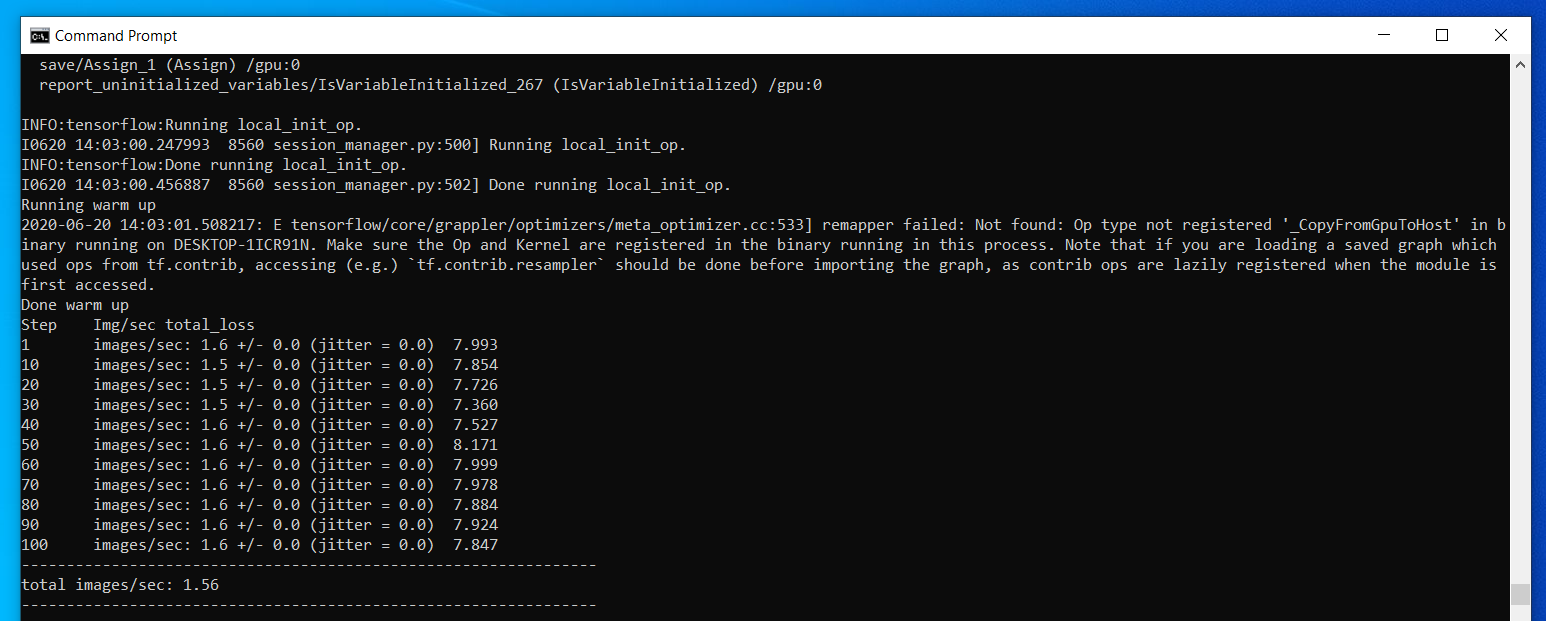
Intel UHD Graphics 620 - Integrated GPU
Same steps as for the RX 580 but with “–batch_size=16” so that it fits into memory
As you can see performance is also quite low, in comparaison the CPU version (Intel i7-8550U, without the use of AVX2 instructions) runs at 2.21 images/s
If you want to see the YOLO sample provided by Microsoft in action:
Conclusion
As you may have noticed from the screenshots there is this error
Op type not registered '_CopyFromGpuToHost'
I reported the error and the RX 580 performance results on DirectML’s issue page
They state that there is still some ops that are not implemented yet which explains the low performance.
Although there is still lots of optimizations work that needs to be done, the DirectML backend for Tensorflow is a very useful initative from Microsoft as it will enable a lot more users to leverage their GPUs for Machine Learning that would have otherwise very little alternatives. I recommend you test DirectML out and report the results for your GPU on their issue’s page
tags: DirectML - AMD - Intel - Windows - tensorflow - machine learning