Impala CNN Model - better performance for Reinforcement Learning
by Mathieu Poliquin

In my recent video about training AI models on video games I said I would test the the impala CNN model in a later video. So I ran some tests comparing the Nature CNN model to the Impala CNN model on four games, in this case:
- Pong
- Berzerk
- Mortal Kombat 2
- Super Mario Bros 2 Japan version
- WWF Wrestlemania The Arcade Game
First some context, almost 3 years ago OpenAI created a environement called CoinRun in order to more effectively test the generalization capabilities of Reinforcement Learning. So basically you need an environement that can generate a large amount of procedural levels that are similar enough to test generalization and that is what CoinRun does.
Before looking at their test results. Here is an overview of the two architectures that we are going to compare. Click on the links if want to see the code in OpenAI’s baselines.
Nature CNN, the name is because of the DeepMind’s Nature paper where they first used that model is a 1.7M parameter model with the 3 filters and one fully connected layer of 512
So it’s a pretty simple model but is efficient on simple retro games and doesn’t use lots of VRAM and GPU compute power, you can use it easily on an NVIDIA Pascal based laptop GPU, with only 2GB vram such as the MX150 which I have on my own laptop.
Now the impala model is deeper. It’s named after DeepMind’s Impala RL framework. The two key differences are the max pooling layer and residual blocks. Max pooling is not in the nature CNN model, some say it’s because it might cause some loss of spatial information that are maybe neccessary in a RL context but not for image recongnition, but in practice it seems it can help performance because it simplifies the representation. There is no clear answer to this topic yet, but for sure it’s worth testing on and off for your specific tasks. and in case of retro games, as you will see, it seems to improve performance.
For residual blocks they are used to avoid vanishing gradients, which is especially a problem in bigger neural nets. https://towardsdatascience.com/the-vanishing-gradient-problem-69bf08b15484
Now lets look at OpenAI’s test results, taken from their blog post https://openai.com/blog/quantifying-generalization-in-reinforcement-learning/
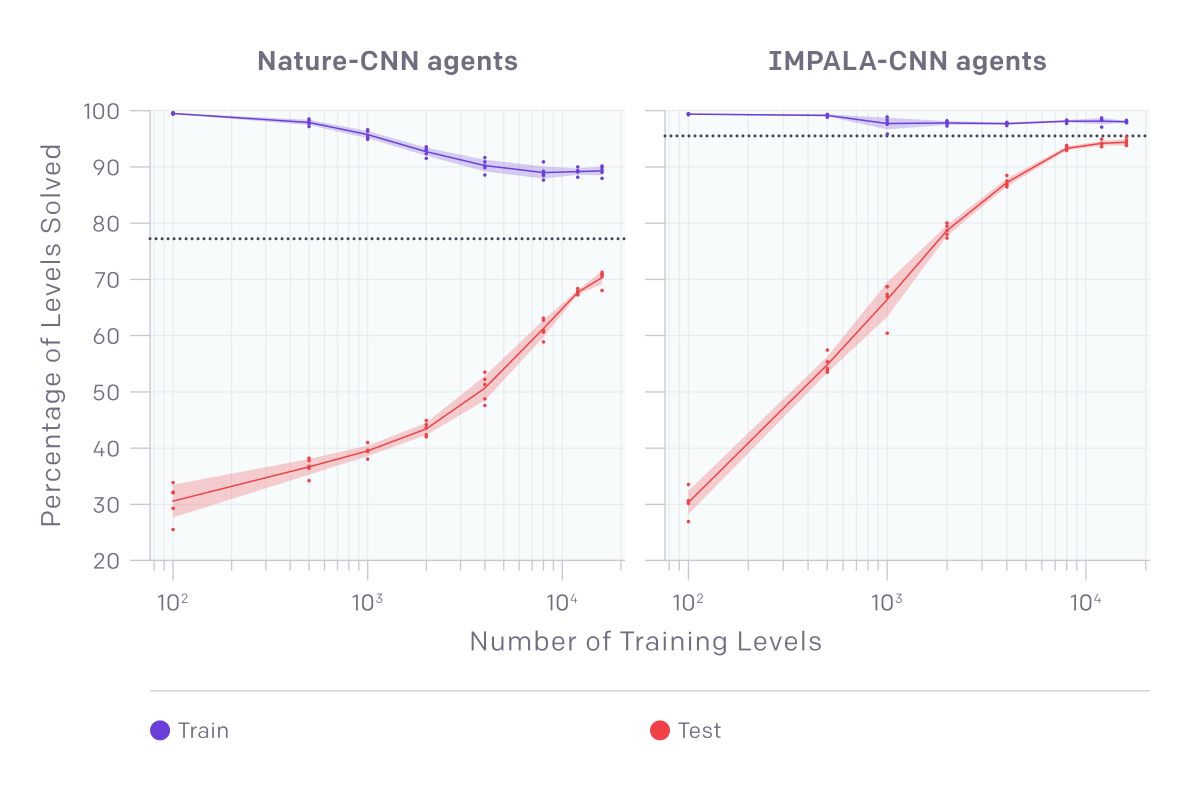
Games
Impala CNN had the most success on Pong and MK2. Please note that Pong atari 2600 env doesn’t not crop the scores at the top from the input image which makes it a harder env to solve then what you see in some papers were they crop the frame.
Mortal Kombat II - Genesis
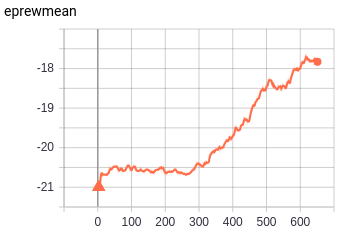
Pong - Atari 2600
Pong CNN - PPO2 - 2M timesteps:
python3 -m baselines.run --alg=ppo2 --network=cnn --num_env=24 --env=Pong-Atari2600 --num_timesteps=2e6
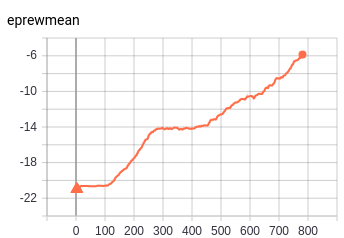
Pong Impala CNN - PPO2 - 2M timesteps:
python3 -m baselines.run --alg=ppo2 --network=impala_cnn --num_env=20 --env=Pong-Atari2600 --num_timesteps=2e6
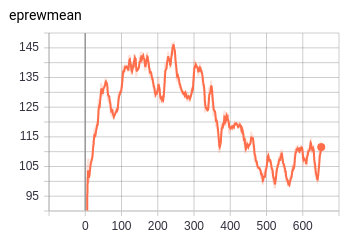
Mortal Kombat II - Genesis
MK2 CNN - PPO2 - 2M timesteps:
python3 -m baselines.run --alg=ppo2 --network=cnn --num_env=24 --env=MortalKombatII-Genesis --num_timesteps=2e6
MK2 Impala CNN - PPO2 - 2M timesteps:
python3 -m baselines.run --alg=ppo2 --network=impala_cnn --num_env=20 --env=MortalKombatII-Genesis --num_timesteps=2e6
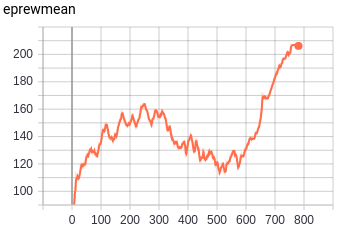
EDIT 2022:
Berzerk - Atari 2600
I did some longer test with Berzerk - Atari2600 Each tests are with 100M timesteps. As you can see, in the long run Impala CNN arhitecture performs much better then the other two even though it learns more slowly at the beginning
python3 -m baselines.run --alg=ppo2 --network=impala_cnn --num_env=20 --env=Berzerk-Atari2600 --num_timesteps=1e8
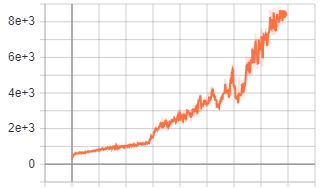
--network=cnn
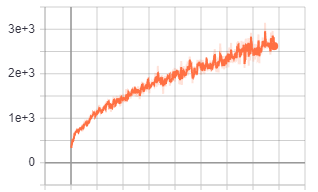
--network=cnn_small
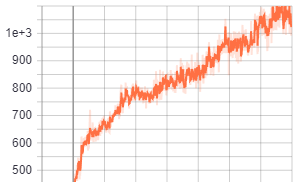
You can check more details about the tests here with timestamps in the description:
Memory usage and performance
Memory usage is slighly under 5400 GB (~5GB if dont count memory used by Ubuntu) for Impala CNN model with 20 environements. For one environement the memory is at ~1.2GB (~0.9 GB if dont count memory used by Ubuntu), so it can fit on a laptop but the training FPS is much lower (arount ~120 for one env depending on your CPU) which means for more complex games the training time will be very long.
Conclusion
Despite taking more compute resources and memory I think the Impala model is worth trying. In my case, from this point on I will use this model for my basics tests on retro games, it clearly performs better
tags: OpenAI - Impala - CNN - model - baselines - retro - performance - machine learning