RX 6700s for Machine Learning using ROCm 5.3
by Mathieu Poliquin
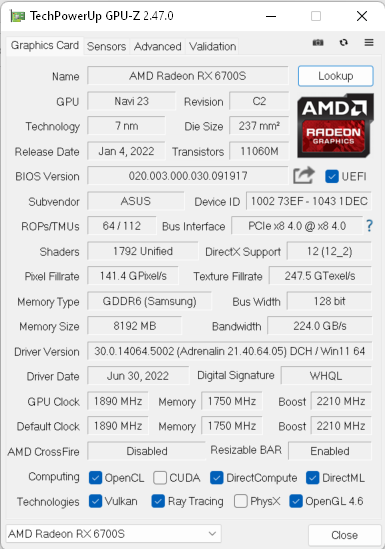
Hardware specs used for the tests:
- AMD RX 6700s 8GB DDR6
- AMD 6800HS 8C/16T
- 2x 8GB DDR5 @4800Mhz
- 512GB SSD
Software specs:
- OpenSuse Tumbleweed
- Kernel: 5.19.2-1-default
- Tensorflow 2.9.2
Video form of installation instructions if you prefer (for Ubuntu):
Installation
As you problably know ROCm is only supported on Linux and is not yet supported with Windows’ WSL2 / Hyper-V unlike CUDA.
As of this writing, Ubuntu 22.04 still have issues with ROCm I chose to use OpenSuse Tumbleweed (5.19.2-1-default kernel) as some users on the ROCm github issues page reported that it works
Official rocm install guide: https://docs.amd.com/bundle/ROCm_Installation_Guidev5.0/page/How_To_Install_ROCm.html#_Installation_Methods
Installing ROCm (OpenSuse Tumbleweed)
We can use the amdgpu-install script for SLE15 (SUSE Linux Enterprise Server 15), it works on Tumbleweed
This will install the AMD installer script
sudo zypper --no-gpg-checks install https://repo.radeon.com/amdgpu-install/22.20.3/sle/15.4/amdgpu-install-22.20.50203-1.noarch.rpm
Next, we are ready to install rocm (this will install the kernel-mode drivers as well)
sudo amdgpu-install --usecase=rocm
IMPORTANT Since the RX 6700s is not explicitly supported by ROCm for now (although other RDNA2 architecture based cards are supported since ROCm 5.0) you need to set this in the terminal:
export HSA_OVERRIDE_GFX_VERSION=10.3.0
Installing ROCm (Ubuntu 22.04 / 22.10)
sudo apt-get update
wget https://repo.radeon.com/amdgpu-install/5.3/ubuntu/jammy/amdgpu-install_5.3.50300-1_all.deb
sudo apt-get install ./amdgpu-install_5.3.50300-1_all.deb
sudo amdgpu-install --usecase=rocm,hip,mllib --no-dkms
sudo usermod -a -G video $LOGNAME
sudo usermod -a -G render $LOGNAME
Note: You need to add your user to the render and video groups so you can access GPU resources
Installing tensorflow and pytorch
Installing tensorflow is simple:
pip3 install tensorflow-rocm
In my case it installed: 2.9.2 (the latest available as of the writing of this post)
For pytorch simply use the version for rocm 5.1.1 (the latest available as of the writing of this post):
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/rocm5.1.1
Errors
You might get RCCL missing lib import errors in various forms when you run Tensorflow.
to fix that:
sudo zypper install rccl
Set this variable in the terminal:
export LD_LIBRARY_PATH=/opt/rocm/lib
RESNET 50, Alexnet benchmarks
You can get the benchmarks here:
git clone https://github.com/tensorflow/benchmarks.git
cd benchmarks/scripts/tf_cnn_benchmarks
python3 tf_cnn_benchmarks.py --num_gpus=1 --batch_size=32 --model=resnet50
Step Img/sec total_loss
1 images/sec: 99.3 +/- 0.0 (jitter = 0.0) 7.765
10 images/sec: 99.5 +/- 0.1 (jitter = 0.2) 8.049
20 images/sec: 99.3 +/- 0.1 (jitter = 0.3) 7.808
30 images/sec: 98.8 +/- 0.2 (jitter = 0.6) 7.976
40 images/sec: 98.4 +/- 0.2 (jitter = 1.2) 7.591
50 images/sec: 98.1 +/- 0.2 (jitter = 1.1) 7.549
60 images/sec: 97.9 +/- 0.2 (jitter = 1.0) 7.819
70 images/sec: 97.7 +/- 0.1 (jitter = 0.7) 7.819
80 images/sec: 97.6 +/- 0.1 (jitter = 0.5) 7.848
90 images/sec: 97.5 +/- 0.1 (jitter = 0.5) 8.026
100 images/sec: 97.4 +/- 0.1 (jitter = 0.5) 8.030
----------------------------------------------------------------
total images/sec: 97.40
----------------------------------------------------------------
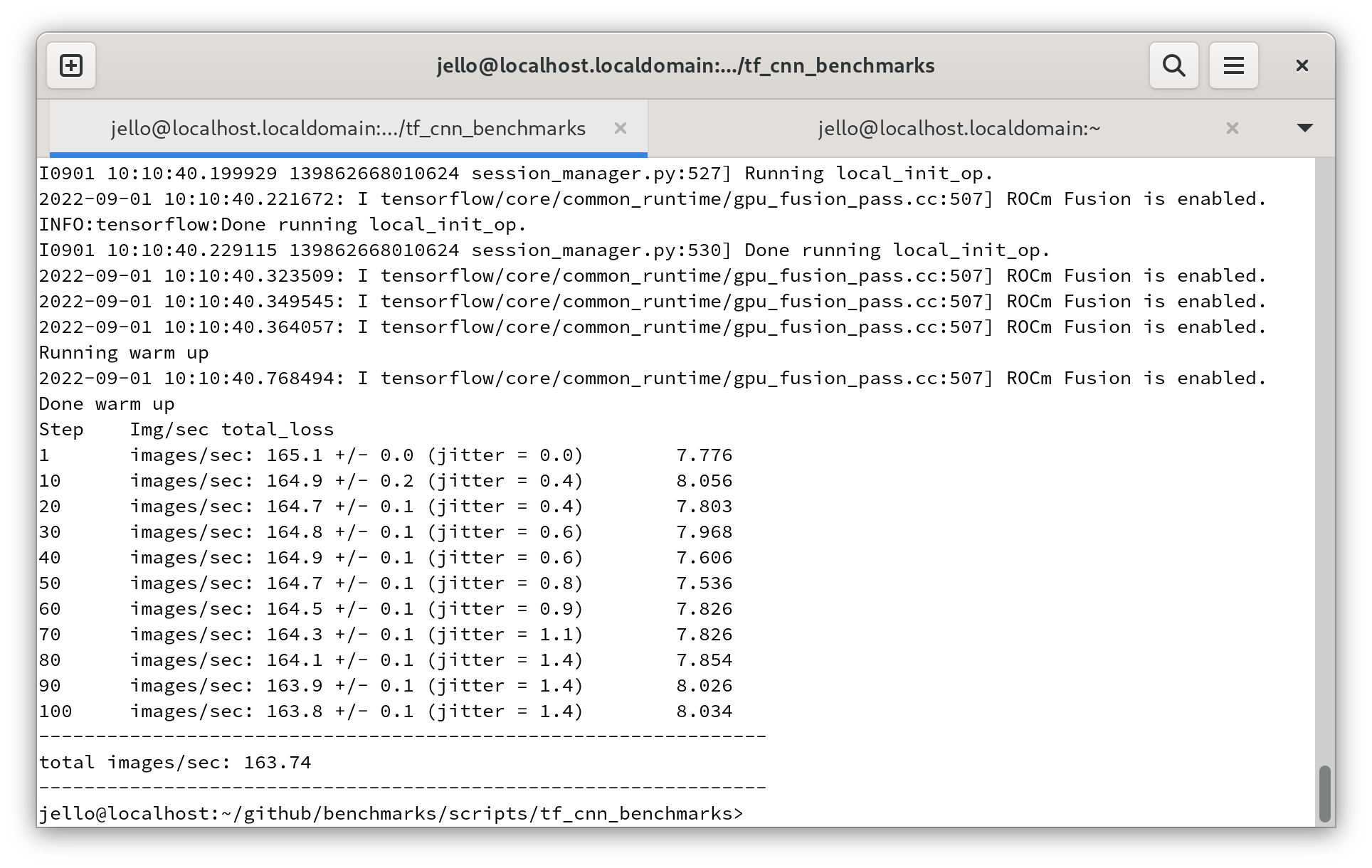
For 16 bit float precision:
python3 tf_cnn_benchmarks.py --num_gpus=1 --batch_size=32 --model=resnet50 --use_fp16
Like the RTX cards It supports 16 bit precision which is faster:
Alexnet test
python3 tf_cnn_benchmarks.py --num_gpus=1 --batch_size=32 --model=alexnet
Step Img/sec total_loss
1 images/sec: 637.6 +/- 0.0 (jitter = 0.0) nan
10 images/sec: 635.5 +/- 2.1 (jitter = 2.3) nan
20 images/sec: 631.9 +/- 2.2 (jitter = 4.1) nan
30 images/sec: 630.4 +/- 1.9 (jitter = 4.4) nan
40 images/sec: 630.6 +/- 1.5 (jitter = 4.5) nan
50 images/sec: 630.2 +/- 1.3 (jitter = 4.6) nan
60 images/sec: 630.3 +/- 1.3 (jitter = 4.7) nan
70 images/sec: 631.0 +/- 1.2 (jitter = 5.1) nan
80 images/sec: 630.9 +/- 1.0 (jitter = 5.1) nan
90 images/sec: 630.8 +/- 1.0 (jitter = 5.1) nan
100 images/sec: 631.7 +/- 1.0 (jitter = 5.7) nan
----------------------------------------------------------------
total images/sec: 630.92
----------------------------------------------------------------
performance issues
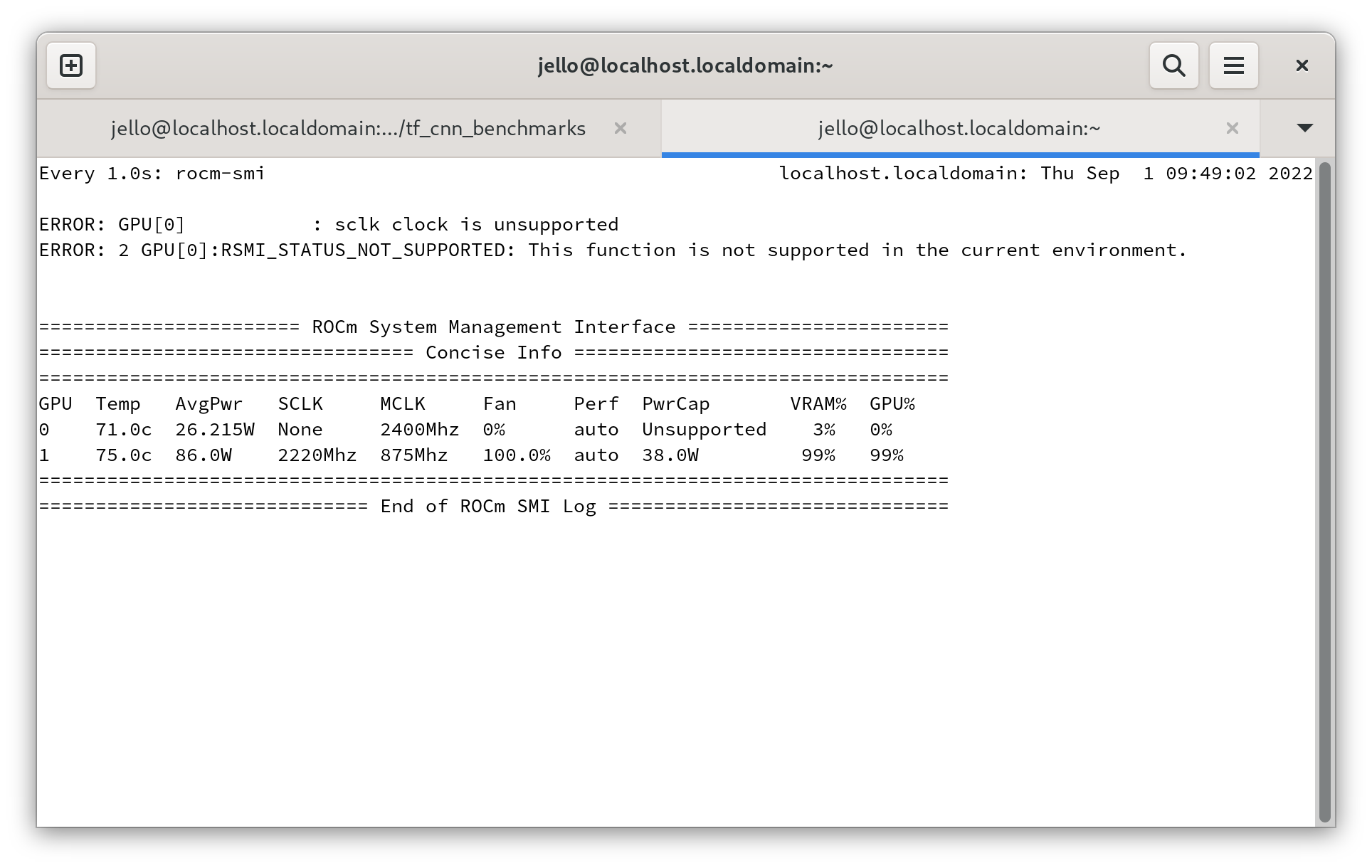
If for some reasons your card does not set the highest clock available make sure the perflevel is set to high using rocm-smi
rocm-smi --setperflevel high
But even with this settings there is still a problem with the Memory clock, it caps at 875Mhz, meanwhile the maximum of this card is twice that (see GPU-Z screenshot at the beginning).
After some testing it seems to be an issue at the driver level because I get the same capped Memory clock when I run benchmarks such as Uniengine or Geekbench 5, also same thing happens on Ubuntu 20.04 with a differnet kernel (5.15)
when I use rocm-smi to list the available memory clocks frequencies the maximum is 875Mhz, meanwhile the main memory clock is the correct value
So currently the RX 6700s have similar performance to the RX 580 8GB for 32 bit precision when it should be 40% higher according to my estimates, this is probably due to the memory clock issue and the fact that RDNA 2 cards are just recently supported.
Also for your CPU (On Ubuntu):
You can use cpupower app to set maximum performance state for your CPU, in some cases (when your CPU needs to do lots of work to feed your GPU) it does make a difference.
sudo apt install cpupower-gui
You can double check if settings where applied correctly:
cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
cat /proc/cpuinfo | grep "MHz"
Also make sure your GPU driver is the most recent:
dpkg -l xserver-xorg-video-amdgpu
For pytorch you can play with the number of threads, by default it can be too high expecially when you are using the GPU
export OMP_NUM_THREADS=1
Bandwidth test
Host to device transfer is 14GB/s, seems to be in line with the specs; PCIE 4.0 8x
Command used
/opt/rocm/bin/rocm-bandwidth-test
Dump:
......................
RocmBandwidthTest Version: 2.6.0
Launch Command is: /opt/rocm/bin/rocm-bandwidth-test (rocm_bandwidth -a + rocm_bandwidth -A)
Device: 0, AMD Ryzen 7 6800HS with Radeon Graphics
Device: 1, AMD Radeon RX 6700S, GPU-XX, 03:0.0
Device: 2, , GPU-XX, 07:0.0
Inter-Device Access
D/D 0 1 2
0 1 1 1
1 1 1 1
2 1 1 1
Inter-Device Numa Distance
D/D 0 1 2
0 0 20 20
1 20 0 40
2 20 40 0
Unidirectional copy peak bandwidth GB/s
D/D 0 1 2
0 N/A 14.186 30.722
1 14.280 201.176 36.747
2 30.161 35.270 58.392
Bidirectional copy peak bandwidth GB/s
D/D 0 1 2
0 N/A 25.843 30.384
1 25.843 N/A 70.546
2 30.384 70.546 N/A
Rocm-smi
In case you are new to ROCm, the AMD alternative to nvidia-smi is rocm-smi
rocm-smi
if you want to use view updates in a loop
watch -n 1 rocm-smi
extra command dumps
rocminfo
rocminfo
[37mROCk module is loaded[0m
=====================
HSA System Attributes
=====================
Runtime Version: 1.1
System Timestamp Freq.: 1000.000000MHz
Sig. Max Wait Duration: 18446744073709551615 (0xFFFFFFFFFFFFFFFF) (timestamp count)
Machine Model: LARGE
System Endianness: LITTLE
==========
HSA Agents
==========
*******
Agent 1
*******
Name: AMD Ryzen 7 6800HS with Radeon Graphics
Uuid: CPU-XX
Marketing Name: AMD Ryzen 7 6800HS with Radeon Graphics
Vendor Name: CPU
Feature: None specified
Profile: FULL_PROFILE
Float Round Mode: NEAR
Max Queue Number: 0(0x0)
Queue Min Size: 0(0x0)
Queue Max Size: 0(0x0)
Queue Type: MULTI
Node: 0
Device Type: CPU
Cache Info:
L1: 32768(0x8000) KB
Chip ID: 0(0x0)
Cacheline Size: 64(0x40)
Max Clock Freq. (MHz): 3200
BDFID: 0
Internal Node ID: 0
Compute Unit: 16
SIMDs per CU: 0
Shader Engines: 0
Shader Arrs. per Eng.: 0
WatchPts on Addr. Ranges:1
Features: None
Pool Info:
Pool 1
Segment: GLOBAL; FLAGS: FINE GRAINED
Size: 15595192(0xedf6b8) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
Pool 2
Segment: GLOBAL; FLAGS: KERNARG, FINE GRAINED
Size: 15595192(0xedf6b8) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
Pool 3
Segment: GLOBAL; FLAGS: COARSE GRAINED
Size: 15595192(0xedf6b8) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
ISA Info:
*******
Agent 2
*******
Name: gfx1032
Uuid: GPU-XX
Marketing Name: AMD Radeon RX 6700S
Vendor Name: AMD
Feature: KERNEL_DISPATCH
Profile: BASE_PROFILE
Float Round Mode: NEAR
Max Queue Number: 128(0x80)
Queue Min Size: 64(0x40)
Queue Max Size: 131072(0x20000)
Queue Type: MULTI
Node: 1
Device Type: GPU
Cache Info:
L1: 16(0x10) KB
L2: 2048(0x800) KB
L3: 32768(0x8000) KB
Chip ID: 29679(0x73ef)
Cacheline Size: 64(0x40)
Max Clock Freq. (MHz): 2435
BDFID: 768
Internal Node ID: 1
Compute Unit: 28
SIMDs per CU: 2
Shader Engines: 4
Shader Arrs. per Eng.: 2
WatchPts on Addr. Ranges:4
Features: KERNEL_DISPATCH
Fast F16 Operation: TRUE
Wavefront Size: 32(0x20)
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Max Waves Per CU: 32(0x20)
Max Work-item Per CU: 1024(0x400)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 4294967295(0xffffffff)
y 4294967295(0xffffffff)
z 4294967295(0xffffffff)
Max fbarriers/Workgrp: 32
Pool Info:
Pool 1
Segment: GLOBAL; FLAGS: COARSE GRAINED
Size: 8372224(0x7fc000) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Alignment: 4KB
Accessible by all: FALSE
Pool 2
Segment: GROUP
Size: 64(0x40) KB
Allocatable: FALSE
Alloc Granule: 0KB
Alloc Alignment: 0KB
Accessible by all: FALSE
ISA Info:
ISA 1
Name: amdgcn-amd-amdhsa--gfx1032
Machine Models: HSA_MACHINE_MODEL_LARGE
Profiles: HSA_PROFILE_BASE
Default Rounding Mode: NEAR
Default Rounding Mode: NEAR
Fast f16: TRUE
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 4294967295(0xffffffff)
y 4294967295(0xffffffff)
z 4294967295(0xffffffff)
FBarrier Max Size: 32
*******
Agent 3
*******
Name: gfx1035
Uuid: GPU-XX
Marketing Name:
Vendor Name: AMD
Feature: KERNEL_DISPATCH
Profile: BASE_PROFILE
Float Round Mode: NEAR
Max Queue Number: 128(0x80)
Queue Min Size: 64(0x40)
Queue Max Size: 131072(0x20000)
Queue Type: MULTI
Node: 2
Device Type: GPU
Cache Info:
L1: 16(0x10) KB
L2: 2048(0x800) KB
Chip ID: 5761(0x1681)
Cacheline Size: 64(0x40)
Max Clock Freq. (MHz): 2200
BDFID: 1792
Internal Node ID: 2
Compute Unit: 12
SIMDs per CU: 2
Shader Engines: 2
Shader Arrs. per Eng.: 2
WatchPts on Addr. Ranges:4
Features: KERNEL_DISPATCH
Fast F16 Operation: TRUE
Wavefront Size: 32(0x20)
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Max Waves Per CU: 32(0x20)
Max Work-item Per CU: 1024(0x400)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 4294967295(0xffffffff)
y 4294967295(0xffffffff)
z 4294967295(0xffffffff)
Max fbarriers/Workgrp: 32
Pool Info:
Pool 1
Segment: GLOBAL; FLAGS: COARSE GRAINED
Size: 524288(0x80000) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Alignment: 4KB
Accessible by all: FALSE
Pool 2
Segment: GROUP
Size: 64(0x40) KB
Allocatable: FALSE
Alloc Granule: 0KB
Alloc Alignment: 0KB
Accessible by all: FALSE
ISA Info:
ISA 1
Name: amdgcn-amd-amdhsa--gfx1035
Machine Models: HSA_MACHINE_MODEL_LARGE
Profiles: HSA_PROFILE_BASE
Default Rounding Mode: NEAR
Default Rounding Mode: NEAR
Fast f16: TRUE
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 4294967295(0xffffffff)
y 4294967295(0xffffffff)
z 4294967295(0xffffffff)
FBarrier Max Size: 32
*** Done ***
clinfo
/opt/rocm/opencl/bin/clinfo
Number of platforms: 1
Platform Profile: FULL_PROFILE
Platform Version: OpenCL 2.1 AMD-APP (3452.0)
Platform Name: AMD Accelerated Parallel Processing
Platform Vendor: Advanced Micro Devices, Inc.
Platform Extensions: cl_khr_icd cl_amd_event_callback
Platform Name: AMD Accelerated Parallel Processing
Number of devices: 2
Device Type: CL_DEVICE_TYPE_GPU
Vendor ID: 1002h
Board name: AMD Radeon RX 6700S
Device Topology: PCI[ B#3, D#0, F#0 ]
Max compute units: 14
Max work items dimensions: 3
Max work items[0]: 1024
Max work items[1]: 1024
Max work items[2]: 1024
Max work group size: 256
Preferred vector width char: 4
Preferred vector width short: 2
Preferred vector width int: 1
Preferred vector width long: 1
Preferred vector width float: 1
Preferred vector width double: 1
Native vector width char: 4
Native vector width short: 2
Native vector width int: 1
Native vector width long: 1
Native vector width float: 1
Native vector width double: 1
Max clock frequency: 2435Mhz
Address bits: 64
Max memory allocation: 7287183768
Image support: Yes
Max number of images read arguments: 128
Max number of images write arguments: 8
Max image 2D width: 16384
Max image 2D height: 16384
Max image 3D width: 16384
Max image 3D height: 16384
Max image 3D depth: 8192
Max samplers within kernel: 29679
Max size of kernel argument: 1024
Alignment (bits) of base address: 1024
Minimum alignment (bytes) for any datatype: 128
Single precision floating point capability
Denorms: Yes
Quiet NaNs: Yes
Round to nearest even: Yes
Round to zero: Yes
Round to +ve and infinity: Yes
IEEE754-2008 fused multiply-add: Yes
Cache type: Read/Write
Cache line size: 64
Cache size: 16384
Global memory size: 8573157376
Constant buffer size: 7287183768
Max number of constant args: 8
Local memory type: Scratchpad
Local memory size: 65536
Max pipe arguments: 16
Max pipe active reservations: 16
Max pipe packet size: 2992216472
Max global variable size: 7287183768
Max global variable preferred total size: 8573157376
Max read/write image args: 64
Max on device events: 1024
Queue on device max size: 8388608
Max on device queues: 1
Queue on device preferred size: 262144
SVM capabilities:
Coarse grain buffer: Yes
Fine grain buffer: Yes
Fine grain system: No
Atomics: No
Preferred platform atomic alignment: 0
Preferred global atomic alignment: 0
Preferred local atomic alignment: 0
Kernel Preferred work group size multiple: 32
Error correction support: 0
Unified memory for Host and Device: 0
Profiling timer resolution: 1
Device endianess: Little
Available: Yes
Compiler available: Yes
Execution capabilities:
Execute OpenCL kernels: Yes
Execute native function: No
Queue on Host properties:
Out-of-Order: No
Profiling : Yes
Queue on Device properties:
Out-of-Order: Yes
Profiling : Yes
Platform ID: 0x7fb3dd53ed70
Name: gfx1032
Vendor: Advanced Micro Devices, Inc.
Device OpenCL C version: OpenCL C 2.0
Driver version: 3452.0 (HSA1.1,LC)
Profile: FULL_PROFILE
Version: OpenCL 2.0
Extensions: cl_khr_fp64 cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_int64_base_atomics cl_khr_int64_extended_atomics cl_khr_3d_image_writes cl_khr_byte_addressable_store cl_khr_fp16 cl_khr_gl_sharing cl_amd_device_attribute_query cl_amd_media_ops cl_amd_media_ops2 cl_khr_image2d_from_buffer cl_khr_subgroups cl_khr_depth_images cl_amd_copy_buffer_p2p cl_amd_assembly_program
Device Type: CL_DEVICE_TYPE_GPU
Vendor ID: 1002h
Board name:
Device Topology: PCI[ B#7, D#0, F#0 ]
Max compute units: 6
Max work items dimensions: 3
Max work items[0]: 1024
Max work items[1]: 1024
Max work items[2]: 1024
Max work group size: 256
Preferred vector width char: 4
Preferred vector width short: 2
Preferred vector width int: 1
Preferred vector width long: 1
Preferred vector width float: 1
Preferred vector width double: 1
Native vector width char: 4
Native vector width short: 2
Native vector width int: 1
Native vector width long: 1
Native vector width float: 1
Native vector width double: 1
Max clock frequency: 2200Mhz
Address bits: 64
Max memory allocation: 456340272
Image support: Yes
Max number of images read arguments: 128
Max number of images write arguments: 8
Max image 2D width: 16384
Max image 2D height: 16384
Max image 3D width: 16384
Max image 3D height: 16384
Max image 3D depth: 8192
Max samplers within kernel: 5761
Max size of kernel argument: 1024
Alignment (bits) of base address: 1024
Minimum alignment (bytes) for any datatype: 128
Single precision floating point capability
Denorms: Yes
Quiet NaNs: Yes
Round to nearest even: Yes
Round to zero: Yes
Round to +ve and infinity: Yes
IEEE754-2008 fused multiply-add: Yes
Cache type: Read/Write
Cache line size: 64
Cache size: 16384
Global memory size: 536870912
Constant buffer size: 456340272
Max number of constant args: 8
Local memory type: Scratchpad
Local memory size: 65536
Max pipe arguments: 16
Max pipe active reservations: 16
Max pipe packet size: 456340272
Max global variable size: 456340272
Max global variable preferred total size: 536870912
Max read/write image args: 64
Max on device events: 1024
Queue on device max size: 8388608
Max on device queues: 1
Queue on device preferred size: 262144
SVM capabilities:
Coarse grain buffer: Yes
Fine grain buffer: Yes
Fine grain system: No
Atomics: No
Preferred platform atomic alignment: 0
Preferred global atomic alignment: 0
Preferred local atomic alignment: 0
Kernel Preferred work group size multiple: 32
Error correction support: 0
Unified memory for Host and Device: 0
Profiling timer resolution: 1
Device endianess: Little
Available: Yes
Compiler available: Yes
Execution capabilities:
Execute OpenCL kernels: Yes
Execute native function: No
Queue on Host properties:
Out-of-Order: No
Profiling : Yes
Queue on Device properties:
Out-of-Order: Yes
Profiling : Yes
Platform ID: 0x7fb3dd53ed70
Name: gfx1035
Vendor: Advanced Micro Devices, Inc.
Device OpenCL C version: OpenCL C 2.0
Driver version: 3452.0 (HSA1.1,LC)
Profile: FULL_PROFILE
Version: OpenCL 2.0
Extensions: cl_khr_fp64 cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_int64_base_atomics cl_khr_int64_extended_atomics cl_khr_3d_image_writes cl_khr_byte_addressable_store cl_khr_fp16 cl_khr_gl_sharing cl_amd_device_attribute_query cl_amd_media_ops cl_amd_media_ops2 cl_khr_image2d_from_buffer cl_khr_subgroups cl_khr_depth_images cl_amd_copy_buffer_p2p cl_amd_assembly_program
tags: RX 6700s - ROCm - Machine Learning - tensorflow - resnet50