Proxmox performance vs Native for Machine Learning
by Mathieu Poliquin
As stated in the last post I made some performance test with proxmox and you can find the results. For those in a hurry the conclusion is that performance is very close to native and now proxmox is what I use on my home server
Hardware specs:
- Intel 12700k (Alder Lake)
- iGPU: Intel UHD Graphics 770
- Huananzhi B660M Plus motherboard
- 32GB DDR4 3200Mhz
- MSI RTX 20260 12GB
Software specs:
- Ubuntu 22.04
- Kernel: 6.2.0-31-generic
- NVIDIA driver: 535.86.05
- Proxmox VE 8.0.3
- Windows 11
Settings used
For the gpu passthrough I used the settings I described in my previous blog post on how to setup it up.
Windows 11 VM:
- CPU type: host
- BIOS: UEFI
- Machine type: q35
Ubuntu 22.04 VM:
- CPU type: host
- BIOS: SeaBIOS
- Machine Type: i440fx
As you noticed CPU type is set to host, this is important to get similar results as below.
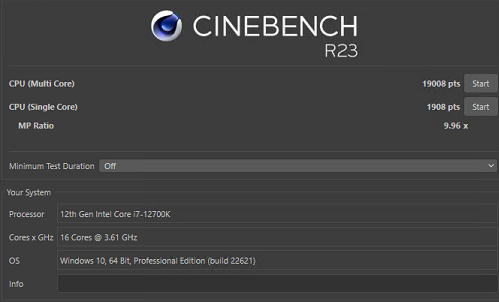
Cinebench r23
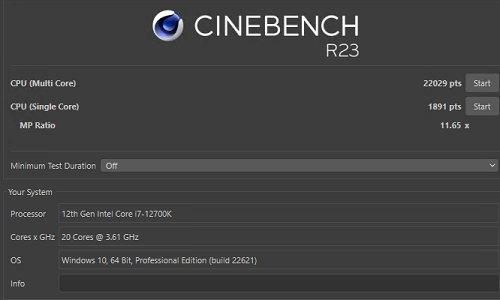
On native Windows I got 22400 as highest score for r23 which represents 1.8% difference
For the test with no e-cores, I just set the affinity to the first 16 core/threads as the last 4 are e cores as opposed to disabling them in the BIOS.
Machine learning
https://github.com/MatPoliquin/stable-retro-scripts.git
python3 model_trainer.py --env=Pong-Atari2600 --num_timesteps=10_000_000 --num_env=20
| Test | Proxmox | Native |
|---|---|---|
| Pong | 2062 fps/s | 2192 fps/s |
Pytorch benchmark: https://github.com/pytorch/benchmark
python run.py [MODELNAME] -d cuda -t eval
| Test | Proxmox (ms) | Native (ms) |
|---|---|---|
| llama | 15.950 | 16.315 |
| resnet50 | 33.554 | 32.152 |
| resnet152 | 78.817 | 77.712 |
| vgg16 | 8.983 | 9.153 |
| hf_gpt2 | 30.571 | 29.933 |
| hf_gpt2_large | 148.251 | 147.398 |
| hf_bert | 10.905 | 11.136 |
| yolov3 | 50.128 | 48.884 |
CUDA-Z
CUDA-Z returns similar results to native:
CUDA-Z Report
=============
Version: 0.10.251 64 bit http://cuda-z.sf.net/
OS Version: Linux 6.2.0-31-generic #31~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Wed Aug 16 13:45:26 UTC 2 x86_64
Driver Version: 535.86.05
Driver Dll Version: 12.20 (535.86.05)
Runtime Dll Version: 6.50
Core Information
----------------
Name: NVIDIA GeForce RTX 2060
Compute Capability: 7.5
Clock Rate: 1680 MHz
PCI Location: 0:0:16
Multiprocessors: 34
Threads Per Multiproc.: 1024
Warp Size: 32
Regs Per Block: 65536
Threads Per Block: 1024
Threads Dimensions: 1024 x 1024 x 64
Grid Dimensions: 2147483647 x 65535 x 65535
Watchdog Enabled: Yes
Integrated GPU: No
Concurrent Kernels: Yes
Compute Mode: Default
Stream Priorities: Yes
Memory Information
------------------
Total Global: 11.7401 GiB
Bus Width: 192 bits
Clock Rate: 7001 MHz
Error Correction: No
L2 Cache Size: 48 KiB
Shared Per Block: 48 KiB
Pitch: 2048 MiB
Total Constant: 64 KiB
Texture Alignment: 512 B
Texture 1D Size: 131072
Texture 2D Size: 131072 x 65536
Texture 3D Size: 16384 x 16384 x 16384
GPU Overlap: Yes
Map Host Memory: Yes
Unified Addressing: Yes
Async Engine: No
Performance Information
-----------------------
Memory Copy
Host Pinned to Device: 11.757 GiB/s
Host Pageable to Device: 11.2587 GiB/s
Device to Host Pinned: 12.2091 GiB/s
Device to Host Pageable: 10.8422 GiB/s
Device to Device: 127.455 GiB/s
GPU Core Performance
Single-precision Float: 8515.46 Gflop/s
Double-precision Float: 201.306 Gflop/s
64-bit Integer: 1764.03 Giop/s
32-bit Integer: 6277.72 Giop/s
24-bit Integer: 6212.7 Giop/s
Conclusion
As stated in the intro, for my use cases proxmox performance is quite close to native and is well worth all the benefits of virtualization. In a next update I plan to test ssd speed and also network bandwidth and a bit more ML tasks such as one with stable-diffusion
tags: Proxmox - performance - machine learning - Ubuntu - Windows - Cinebench r23