Machine Learning vs NHL94 (1 on 1 mode)
by Mathieu Poliquin
30 years later, NHL 94 for Sega Genesis, still has a vibrant community around it and it deserves it. It’s a deep game that revolutionised it’s genre back in the days but it’s also a hard game for current Machine Learning algos to beat since rewards are relatively far away compared to Mortal Kombat or Sonic.
I have this long term project to build stronger AI opponent for the game, provide an AI player teammate and also enable AI vs AI competitions.
The first step was to beat the in game AI in the 1 vs 1 rom hack and I am going to explain the solution here.
Let’s dive into it!
The solution I end up using in summary (more details in next sections):
- Use MLPs instead of a CNNs: The problem is that in this game and most sports game you only see part of the field/rink and your player may be off screen which makes it more complicated. Instead I use MLPs and directly feed coordinates and velocities
- Divide the problem: I use two MLPs, one for offense and another for defense and the rest is handled by code. It’s less elegant than one end to end neural net but it’s easier to tweak and get working at first
- Use ML to target a subset of the task : Related to the above point, not everything needs Machine Learning, example: for offence I use ML only for creating a scoring opportunity, not for shooting which is done by code
- Higher quality data: current RL solutions are very data hungry and needs highly varied data in large quantities. The issue is for lots of games there is not much randomization, the levels, AI behavior are always similar. So I added support in the stable-retro API to set values in ram so at each play session I can randomize positions of players.
-
Full source code, install instructions with pretrained models can be found on my [Github project](https://github.com/MatPoliquin/stable-retro-scripts)
if you want to see a video of the AI in action:
Model and algo details
As seen in above screenshot the two MLPs uses these parameters as input (16 in total, normalized [-1,1]) :
- player 1 position x
- player 1 position y
- player 1 velocity x
- player 1 velocity y
- player 2 position x
- player 2 position y
- player 2 velocity x
- player 2 velocity y
- puck position x
- puck position y
- puck velocity x
- puck velocity y
- goalie 2 position x
- goalie 2 position y
- if p1 has puck
- if p2 has puck
Some points:
- Obviously you need velocities because (quote from one of the greatest player of all time): “I skate to where the puck is going to be, not where it has been.” - Wayne Gretzky
- The models were trained for 200M timesteps each (around 16 hours each on my server (hardware details at the end))
- The two models have 143,629 trainable parameters each. I tested with smaller and larger models but with same number of timesteps the performance was lower, I need to do some more rigourous test with longer timesteps
pytorch summary
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Flatten-1 [-1, 16] 0
FlattenExtractor-2 [-1, 16] 0
Linear-3 [-1, 256] 4,352
ReLU-4 [-1, 256] 0
Linear-5 [-1, 256] 65,792
ReLU-6 [-1, 256] 0
Linear-7 [-1, 256] 4,352
ReLU-8 [-1, 256] 0
Linear-9 [-1, 256] 65,792
ReLU-10 [-1, 256] 0
MlpExtractor-11 [[-1, 256], [-1, 256]] 0
Linear-12 [-1, 1] 257
Linear-13 [-1, 12] 3,084
================================================================
Total params: 143,629
Trainable params: 143,629
Non-trainable params: 0
Some points about PPO (stable-baselines3)
- batch_size = (128 * num_env) // 4. Higher batch sizes did not give better results for now, again I need to do more testing with larger timesteps
- ent_coef = 0.01
- n_epochs = 4
- the rest are the defaults of stable-baeselines3 (you can check the details in the source code)
Reward Functions
Example where the AI is using the scoring opportunity model
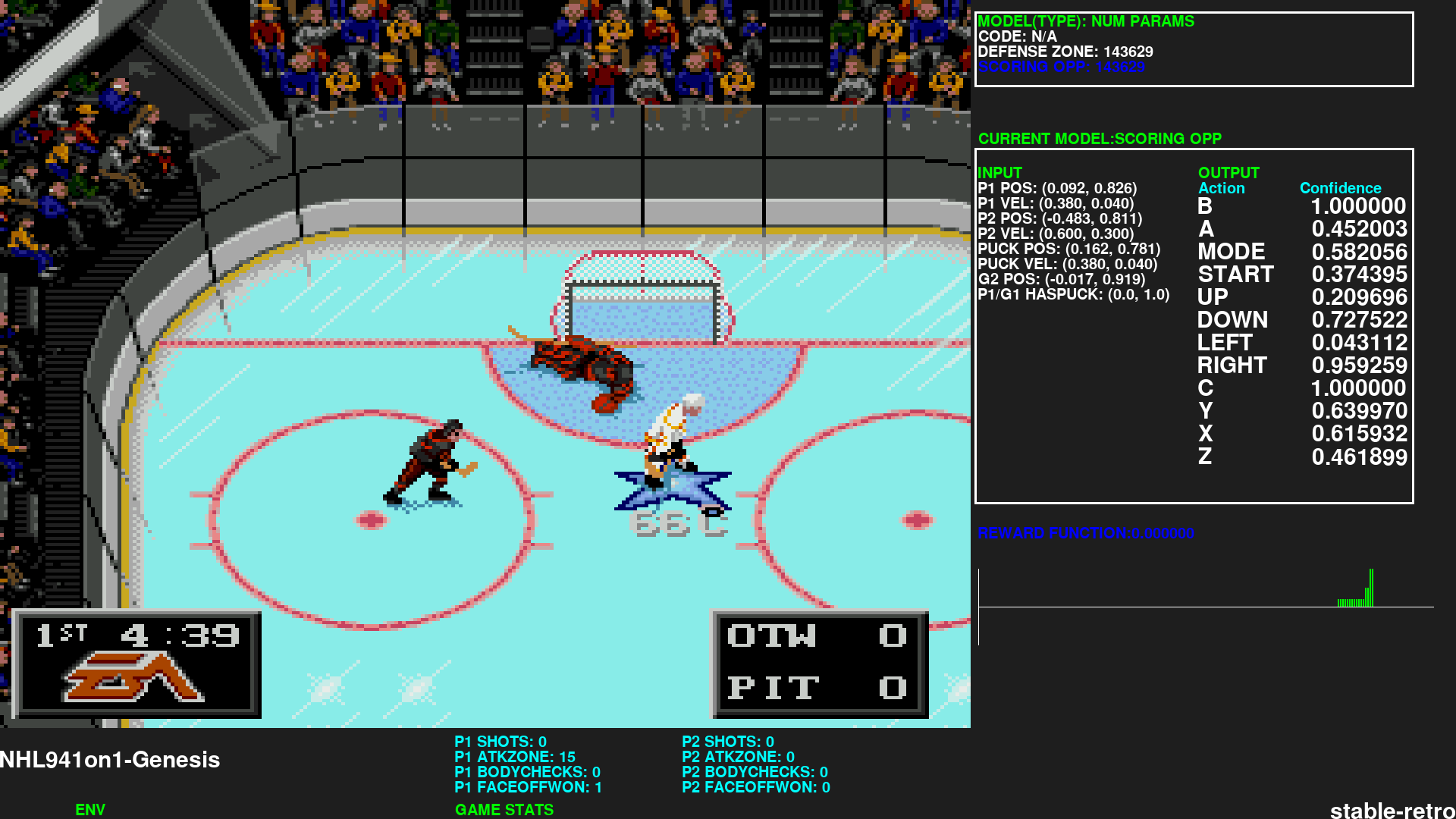
As mentionned earlier, one of the important points is to divide the problem into smaller digestable chunks for models. NHL 94 (and most hockey games) is a game where there is many tricky steps involved in order to score a goal which means rewards are quite rare and current ML algos and models have trouble with that.
If you are curious to know what happens if you just give a reward for a goal here is the reward graph after 2 Billions timesteps!
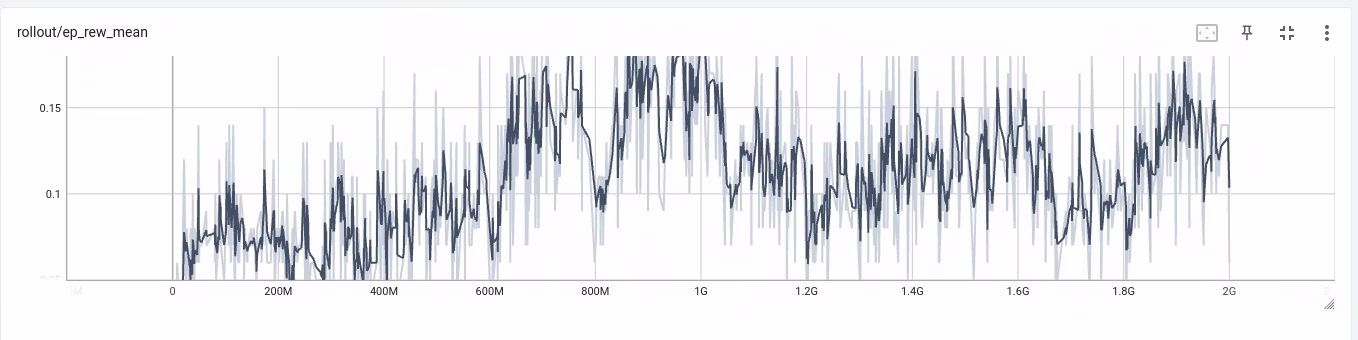
As you can tell the model has trouble learning, that is because the reward is too far off and the steps more complicated than just shooting at the net. Speaking of shooting if you reward for shots, the model learns to shoot easily but it ends taking non quality shots that don’t result in a goal. Now you can reward for quality shots and that is closer to the solution we will use but still not quite…
So the best approach is somehow similar to how professional hockey players think, that is not trying to directly score a goal but focusing on maximizing chances of scoring instead.
For offense I only reward for creating a scoring opportunity (passing across the crease) instead of directly trying to score which is much more effective for current ML algos (since the rewards are much less sparse than goals) but at the expense on finding completly novel solutions. Note that it can still innovate within the strategy you are trying to teach the model and this often enough to be suprising so it’s a good trade off
For now we only have one scoring strategy and that is enough to beat the in game AI, against a human player we need more variety of course to be suprising but even if this single strategy (cross crease) it can be difficult for a human player as the model can be surprising on how it evades the player and executes the strategy
Here is the RF for scoring opportunity and defense:
def rf_scoregoal(state):
rew = 0.0
if state.p2_haspuck or state.g2_haspuck:
rew = -1.0
if state.puck_y < 100:
rew = -1.0
# reward scoring opportunities
if state.player_haspuck and state.p1_y < 230 and state.p1_y > 210:
if state.p1_vel_x >= 30 or state.p1_vel_x <= -30:
rew = 0.2
if state.puck_x > -23 and state.puck_x < 23:
if abs(state.puck_x - state.g2_x) > 7:
rew = 1.0
else:
rew = 0.5
return rew
def rf_defensezone(state):
rew = 0
if state.player_haspuck == False:
if state.distToPuck < state.last_dist:
rew = 1 - (state.distToPuck / 200.0)**0.5
else:
rew = -0.1
else:
rew = 1
if state.p1_bodychecks > state.last_p1_bodychecks:
rew = 1.0
if state.p1_passing > state.last_p1_passing:
rew = 1.0
if not state.player_haspuck:
if state.p1_y > -80:
rew = -1.0
if state.puck_y > -80:
rew = -1.0
if state.goalie_haspuck:
rew = -1.0
if state.p2_score > state.last_p2_score:
rew = -1.0
if state.p2_shots > state.last_p2_shots:
rew = -1.0
return rew
Data
As mentionned above I added support in the retro API to set values in ram, the functionality was already there just not exposed. I wounder why since, provided one has the relevant ram values (can be done with the integration tool) it can dramatically increases the variety of data and training performance
Example for scoring opportunity model. It’s just a few lines but it will make a world of difference. I will update this post with the reward graph without randomization to show a comparaison
It’s available in stable-retro but can be easily back ported to gym-retro if you are still using it
def init_scoregoal(env):
x, y = RandomPosAttackZone()
env.set_value("p2_x", x)
env.set_value("p2_y", y)
x, y = RandomPosAttackZone()
env.set_value("p1_x", x)
env.set_value("p1_y", y)
Conclusion
With this solution we can successfully beat the in-game AI and also give a much greater challenge to human players. The next step will obviously be the 2 on 2 mode which adds an extra layer of complexity with team play Other than that I want to eventually test out transformers and also self-play
Hardware specs:
- Intel 12700k (Alder Lake)
- iGPU: Intel UHD Graphics 770
- Huananzhi B660M Plus motherboard
- 32GB DDR4 3200Mhz
- MSI RTX 20260 12GB
Software specs:
- Ubuntu 22.04
- Kernel: 6.2.0-31-generic
- NVIDIA driver: 535.86.05
python
- stable-baselines3: 2.2.1
- stable-retro: 0.9.2
tags: nhl94 - machine learning - reinforcement learning - stable-baselines - stable-retro